1. TLB
-
TLB = translation-lookaside buffer = address-translation cache
(may be at least partially managed by OS software)
[vs. lower-level data caches (L1, L2, L3) handled completely by hardware]
Assuming a linear page table (i.e. the page table is an array) and a hardware-managed TLB:

2. Cache Example
-
Consider an array of 10 4-byte integers in memory, starting at virtual address 100 = 0b01100100
An 8-bit virtual address space, with 16-byte pages: VA (8) = VPN (4) Offset (4) = 0b0110 0b0100 = 6 4
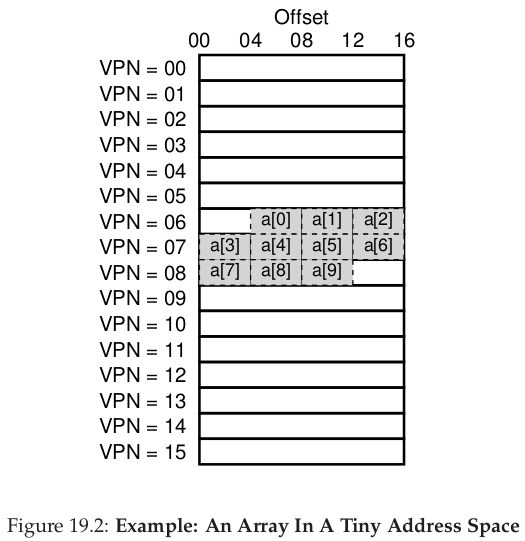
(Above is data cache, TLB cache not shown)
3. Memory Hierarchy Example with TLB and L2 Cache
-
Virtually Indexed, Physically Tagged
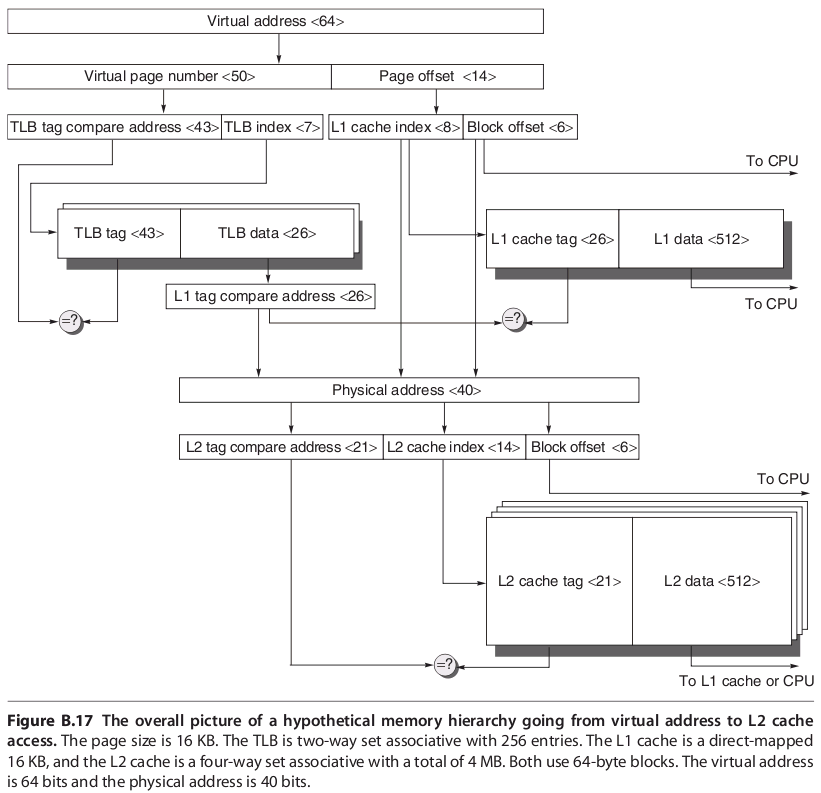
Note: L2 cache tag should be 20 bits (from Hennessy & Patterson)
4. OS Handling TLB Miss

5. TLB Contents
-
TLB entry = VPN, PFN, other bits (valid, protection, dirty, address space ID, ...)

32-bit address space with 4KB pages.
19-bit VPN (+1 bit reserved for kernel), 12-bit offset, translated to 24-bit PFN
224*4KB = 236 = 64 GB physical memory
global bit (G), 8-bit ASID, 3 coherence (C) bits, dirty bit, valid bit.
6. Measuring Cache Effects
-
Homework P19
Consider a 2D array with each row occupying one page of memory:
#include <unistd.h> #include <stdlib.h> ... int main( void) { int nrows = 300, PAGESIZE = sysconf(_SC_PAGESIZE), ncols = PAGESIZE/sizeof(int); int *a = calloc( nrows*ncols, sizeof(int));Note that a dynamically allocated 2D array is stored as a 1D array, soa[row][col]is reallya[row*ncols+col]Accessing the array by rows should be much faster than access by columns, due to TLB and data caching:
// by rows // for( int row = 0; row < nrows; ++row) for( int col = 0; col < ncols; ++col) a[row*ncols+col] += 1;or:// by cols // for( int col = 0; col < ncols; ++col) for( int row = 0; row < nrows; ++row) a[row*ncols+col] += 1;