| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
Developing a parser can be a challenge, especially if you don’t understand the algorithm (see section The Bison Parser Algorithm). This chapter explains how understand and debug a parser.
The first sections focus on the static part of the parser: its structure. They explain how to generate and read the detailed description of the automaton. There are several formats available:
The last section focuses on the dynamic part of the parser: how to enable and understand the parser run-time traces (see section Tracing Your Parser).
| 8.1 Understanding Your Parser | Understanding the structure of your parser. | |
| 8.2 Visualizing Your Parser | Getting a visual representation of the parser. | |
| 8.3 Visualizing your parser in multiple formats | Getting a markup representation of the parser. | |
| 8.4 Tracing Your Parser | Tracing the execution of your parser. |
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
As documented elsewhere (see section The Bison Parser Algorithm) Bison parsers are shift/reduce automata. In some cases (much more frequent than one would hope), looking at this automaton is required to tune or simply fix a parser.
The textual file is generated when the options ‘--report’ or ‘--verbose’ are specified, see Invoking Bison. Its name is made by removing ‘.tab.c’ or ‘.c’ from the parser implementation file name, and adding ‘.output’ instead. Therefore, if the grammar file is ‘foo.y’, then the parser implementation file is called ‘foo.tab.c’ by default. As a consequence, the verbose output file is called ‘foo.output’.
The following grammar file, ‘calc.y’, will be used in the sequel:
%token NUM STR %left '+' '-' %left '*' %% exp: exp '+' exp | exp '-' exp | exp '*' exp | exp '/' exp | NUM ; useless: STR; %% |
bison reports:
calc.y: warning: 1 nonterminal useless in grammar calc.y: warning: 1 rule useless in grammar calc.y:12.1-7: warning: nonterminal useless in grammar: useless calc.y:12.10-12: warning: rule useless in grammar: useless: STR calc.y: conflicts: 7 shift/reduce |
When given ‘--report=state’, in addition to ‘calc.tab.c’, it creates a file ‘calc.output’ with contents detailed below. The order of the output and the exact presentation might vary, but the interpretation is the same.
The first section reports useless tokens, nonterminals and rules. Useless nonterminals and rules are removed in order to produce a smaller parser, but useless tokens are preserved, since they might be used by the scanner (note the difference between “useless” and “unused” below):
Nonterminals useless in grammar
useless
Terminals unused in grammar
STR
Rules useless in grammar
6 useless: STR
|
The next section lists states that still have conflicts.
State 8 conflicts: 1 shift/reduce State 9 conflicts: 1 shift/reduce State 10 conflicts: 1 shift/reduce State 11 conflicts: 4 shift/reduce |
Then Bison reproduces the exact grammar it used:
Grammar
0 $accept: exp $end
1 exp: exp '+' exp
2 | exp '-' exp
3 | exp '*' exp
4 | exp '/' exp
5 | NUM
|
and reports the uses of the symbols:
Terminals, with rules where they appear $end (0) 0 '*' (42) 3 '+' (43) 1 '-' (45) 2 '/' (47) 4 error (256) NUM (258) 5 STR (259) Nonterminals, with rules where they appear
$accept (9)
on left: 0
exp (10)
on left: 1 2 3 4 5, on right: 0 1 2 3 4
|
Bison then proceeds onto the automaton itself, describing each state with its set of items, also known as pointed rules. Each item is a production rule together with a point (‘.’) marking the location of the input cursor.
State 0
0 $accept: . exp $end
NUM shift, and go to state 1
exp go to state 2
|
This reads as follows: “state 0 corresponds to being at the very
beginning of the parsing, in the initial rule, right before the start
symbol (here, exp). When the parser returns to this state right
after having reduced a rule that produced an exp, the control
flow jumps to state 2. If there is no such transition on a nonterminal
symbol, and the lookahead is a NUM, then this token is shifted onto
the parse stack, and the control flow jumps to state 1. Any other
lookahead triggers a syntax error.”
Even though the only active rule in state 0 seems to be rule 0, the
report lists NUM as a lookahead token because NUM can be
at the beginning of any rule deriving an exp. By default Bison
reports the so-called core or kernel of the item set, but if
you want to see more detail you can invoke bison with
‘--report=itemset’ to list the derived items as well:
State 0
0 $accept: . exp $end
1 exp: . exp '+' exp
2 | . exp '-' exp
3 | . exp '*' exp
4 | . exp '/' exp
5 | . NUM
NUM shift, and go to state 1
exp go to state 2
|
In the state 1…
State 1
5 exp: NUM .
$default reduce using rule 5 (exp)
|
the rule 5, ‘exp: NUM;’, is completed. Whatever the lookahead token (‘$default’), the parser will reduce it. If it was coming from State 0, then, after this reduction it will return to state 0, and will jump to state 2 (‘exp: go to state 2’).
State 2
0 $accept: exp . $end
1 exp: exp . '+' exp
2 | exp . '-' exp
3 | exp . '*' exp
4 | exp . '/' exp
$end shift, and go to state 3
'+' shift, and go to state 4
'-' shift, and go to state 5
'*' shift, and go to state 6
'/' shift, and go to state 7
|
In state 2, the automaton can only shift a symbol. For instance, because of the item ‘exp: exp . '+' exp’, if the lookahead is ‘+’ it is shifted onto the parse stack, and the automaton jumps to state 4, corresponding to the item ‘exp: exp '+' . exp’. Since there is no default action, any lookahead not listed triggers a syntax error.
The state 3 is named the final state, or the accepting state:
State 3
0 $accept: exp $end .
$default accept
|
the initial rule is completed (the start symbol and the end-of-input were read), the parsing exits successfully.
The interpretation of states 4 to 7 is straightforward, and is left to the reader.
State 4
1 exp: exp '+' . exp
NUM shift, and go to state 1
exp go to state 8
State 5
2 exp: exp '-' . exp
NUM shift, and go to state 1
exp go to state 9
State 6
3 exp: exp '*' . exp
NUM shift, and go to state 1
exp go to state 10
State 7
4 exp: exp '/' . exp
NUM shift, and go to state 1
exp go to state 11
|
As was announced in beginning of the report, ‘State 8 conflicts: 1 shift/reduce’:
State 8
1 exp: exp . '+' exp
1 | exp '+' exp .
2 | exp . '-' exp
3 | exp . '*' exp
4 | exp . '/' exp
'*' shift, and go to state 6
'/' shift, and go to state 7
'/' [reduce using rule 1 (exp)]
$default reduce using rule 1 (exp)
|
Indeed, there are two actions associated to the lookahead ‘/’: either shifting (and going to state 7), or reducing rule 1. The conflict means that either the grammar is ambiguous, or the parser lacks information to make the right decision. Indeed the grammar is ambiguous, as, since we did not specify the precedence of ‘/’, the sentence ‘NUM + NUM / NUM’ can be parsed as ‘NUM + (NUM / NUM)’, which corresponds to shifting ‘/’, or as ‘(NUM + NUM) / NUM’, which corresponds to reducing rule 1.
Because in deterministic parsing a single decision can be made, Bison arbitrarily chose to disable the reduction, see Shift/Reduce Conflicts. Discarded actions are reported between square brackets.
Note that all the previous states had a single possible action: either shifting the next token and going to the corresponding state, or reducing a single rule. In the other cases, i.e., when shifting and reducing is possible or when several reductions are possible, the lookahead is required to select the action. State 8 is one such state: if the lookahead is ‘*’ or ‘/’ then the action is shifting, otherwise the action is reducing rule 1. In other words, the first two items, corresponding to rule 1, are not eligible when the lookahead token is ‘*’, since we specified that ‘*’ has higher precedence than ‘+’. More generally, some items are eligible only with some set of possible lookahead tokens. When run with ‘--report=lookahead’, Bison specifies these lookahead tokens:
State 8
1 exp: exp . '+' exp
1 | exp '+' exp . [$end, '+', '-', '/']
2 | exp . '-' exp
3 | exp . '*' exp
4 | exp . '/' exp
'*' shift, and go to state 6
'/' shift, and go to state 7
'/' [reduce using rule 1 (exp)]
$default reduce using rule 1 (exp)
|
Note however that while ‘NUM + NUM / NUM’ is ambiguous (which results in the conflicts on ‘/’), ‘NUM + NUM * NUM’ is not: the conflict was solved thanks to associativity and precedence directives. If invoked with ‘--report=solved’, Bison includes information about the solved conflicts in the report:
Conflict between rule 1 and token '+' resolved as reduce (%left '+').
Conflict between rule 1 and token '-' resolved as reduce (%left '-').
Conflict between rule 1 and token '*' resolved as shift ('+' < '*').
|
The remaining states are similar:
State 9
1 exp: exp . '+' exp
2 | exp . '-' exp
2 | exp '-' exp .
3 | exp . '*' exp
4 | exp . '/' exp
'*' shift, and go to state 6
'/' shift, and go to state 7
'/' [reduce using rule 2 (exp)]
$default reduce using rule 2 (exp)
State 10
1 exp: exp . '+' exp
2 | exp . '-' exp
3 | exp . '*' exp
3 | exp '*' exp .
4 | exp . '/' exp
'/' shift, and go to state 7
'/' [reduce using rule 3 (exp)]
$default reduce using rule 3 (exp)
State 11
1 exp: exp . '+' exp
2 | exp . '-' exp
3 | exp . '*' exp
4 | exp . '/' exp
4 | exp '/' exp .
'+' shift, and go to state 4
'-' shift, and go to state 5
'*' shift, and go to state 6
'/' shift, and go to state 7
'+' [reduce using rule 4 (exp)]
'-' [reduce using rule 4 (exp)]
'*' [reduce using rule 4 (exp)]
'/' [reduce using rule 4 (exp)]
$default reduce using rule 4 (exp)
|
Observe that state 11 contains conflicts not only due to the lack of precedence of ‘/’ with respect to ‘+’, ‘-’, and ‘*’, but also because the associativity of ‘/’ is not specified.
Bison may also produce an HTML version of this output, via an XML file and XSLT processing (see section Visualizing your parser in multiple formats).
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
As another means to gain better understanding of the shift/reduce automaton corresponding to the Bison parser, a DOT file can be generated. Note that debugging a real grammar with this is tedious at best, and impractical most of the times, because the generated files are huge (the generation of a PDF or PNG file from it will take very long, and more often than not it will fail due to memory exhaustion). This option was rather designed for beginners, to help them understand LR parsers.
This file is generated when the ‘--graph’ option is specified (see section Invoking Bison). Its name is made by removing ‘.tab.c’ or ‘.c’ from the parser implementation file name, and adding ‘.dot’ instead. If the grammar file is ‘foo.y’, the Graphviz output file is called ‘foo.dot’. A DOT file may also be produced via an XML file and XSLT processing (see section Visualizing your parser in multiple formats).
The following grammar file, ‘rr.y’, will be used in the sequel:
%% exp: a ";" | b "."; a: "0"; b: "0"; |
The graphical output (see fig:graph) is very similar to the textual one, and as such it is easier understood by making direct comparisons between them. See section Debugging Your Parser, for a detailled analysis of the textual report.
Figure 8.1: A graphical rendering of the parser.
The items (pointed rules) for each state are grouped together in graph nodes. Their numbering is the same as in the verbose file. See the following points, about transitions, for examples
When invoked with ‘--report=lookaheads’, the lookahead tokens, when needed, are shown next to the relevant rule between square brackets as a comma separated list. This is the case in the figure for the representation of reductions, below.
The transitions are represented as directed edges between the current and the target states.
Shifts are shown as solid arrows, labelled with the lookahead token for that shift. The following describes a reduction in the ‘rr.output’ file:
State 3
1 exp: a . ";"
";" shift, and go to state 6
|
A Graphviz rendering of this portion of the graph could be:
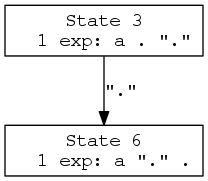
Reductions are shown as solid arrows, leading to a diamond-shaped node bearing the number of the reduction rule. The arrow is labelled with the appropriate comma separated lookahead tokens. If the reduction is the default action for the given state, there is no such label.
This is how reductions are represented in the verbose file ‘rr.output’:
State 1
3 a: "0" . [";"]
4 b: "0" . ["."]
"." reduce using rule 4 (b)
$default reduce using rule 3 (a)
|
A Graphviz rendering of this portion of the graph could be:
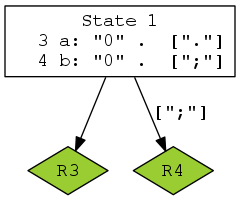
When unresolved conflicts are present, because in deterministic parsing a single decision can be made, Bison can arbitrarily choose to disable a reduction, see Shift/Reduce Conflicts. Discarded actions are distinguished by a red filling color on these nodes, just like how they are reported between square brackets in the verbose file.
The reduction corresponding to the rule number 0 is the acceptation state. It is shown as a blue diamond, labelled “Acc”.
The ‘go to’ jump transitions are represented as dotted lines bearing the name of the rule being jumped to.
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
Bison supports two major report formats: textual output
(see section Understanding Your Parser) when invoked
with option ‘--verbose’, and DOT
(see section Visualizing Your Parser) when invoked with
option ‘--graph’. However,
another alternative is to output an XML file that may then be, with
xsltproc, rendered as either a raw text format equivalent to the
verbose file, or as an HTML version of the same file, with clickable
transitions, or even as a DOT. The ‘.output’ and DOT files obtained via
XSLT have no difference whatsoever with those obtained by invoking
bison with options ‘--verbose’ or ‘--graph’.
The XML file is generated when the options ‘-x’ or ‘--xml[=FILE]’ are specified, see Invoking Bison. If not specified, its name is made by removing ‘.tab.c’ or ‘.c’ from the parser implementation file name, and adding ‘.xml’ instead. For instance, if the grammar file is ‘foo.y’, the default XML output file is ‘foo.xml’.
Bison ships with a ‘data/xslt’ directory, containing XSL Transformation files to apply to the XML file. Their names are non-ambiguous:
Used to output a copy of the DOT visualization of the automaton.
Used to output a copy of the ‘.output’ file.
Used to output an xhtml enhancement of the ‘.output’ file.
Sample usage (requires xsltproc):
$ bison -x gr.y $ bison --print-datadir /usr/local/share/bison $ xsltproc /usr/local/share/bison/xslt/xml2xhtml.xsl gr.xml >gr.html |
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
When a Bison grammar compiles properly but parses “incorrectly”, the
yydebug parser-trace feature helps figuring out why.
| 8.4.1 Enabling Traces | Activating run-time trace support | |
8.4.2 Enabling Debug Traces for mfcalc | Extending mfcalc to support traces
| |
8.4.3 The YYPRINT Macro | Obsolete interface for semantic value reports |
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
There are several means to enable compilation of trace facilities:
YYDEBUGDefine the macro YYDEBUG to a nonzero value when you compile the
parser. This is compliant with POSIX Yacc. You could use
‘-DYYDEBUG=1’ as a compiler option or you could put ‘#define
YYDEBUG 1’ in the prologue of the grammar file (see section The Prologue).
If the %define variable api.prefix is used (see section Multiple Parsers in the Same Program), for instance ‘%define
api.prefix x’, then if CDEBUG is defined, its value controls the
tracing feature (enabled if and only if nonzero); otherwise tracing is
enabled if and only if YYDEBUG is nonzero.
Use the ‘-t’ option when you run Bison (see section Invoking Bison). With ‘%define api.prefix {c}’, it defines CDEBUG to 1,
otherwise it defines YYDEBUG to 1.
Add the %debug directive (see section Bison Declaration Summary). This Bison extension is maintained for backward
compatibility with previous versions of Bison.
Add the ‘%define parse.trace’ directive (see section parse.trace), or pass the ‘-Dparse.trace’ option (see section Bison Options). This is a Bison extension, which is especially useful for languages that don’t use a preprocessor. Unless POSIX and Yacc portability matter to you, this is the preferred solution.
We suggest that you always enable the trace option so that debugging is always possible.
The trace facility outputs messages with macro calls of the form
YYFPRINTF (stderr, format, args) where
format and args are the usual printf format and variadic
arguments. If you define YYDEBUG to a nonzero value but do not
define YYFPRINTF, <stdio.h> is automatically included
and YYFPRINTF is defined to fprintf.
Once you have compiled the program with trace facilities, the way to
request a trace is to store a nonzero value in the variable yydebug.
You can do this by making the C code do it (in main, perhaps), or
you can alter the value with a C debugger.
Each step taken by the parser when yydebug is nonzero produces a
line or two of trace information, written on stderr. The trace
messages tell you these things:
yylex, what kind of token was read.
To make sense of this information, it helps to refer to the automaton description file (see section Understanding Your Parser). This file shows the meaning of each state in terms of positions in various rules, and also what each state will do with each possible input token. As you read the successive trace messages, you can see that the parser is functioning according to its specification in the listing file. Eventually you will arrive at the place where something undesirable happens, and you will see which parts of the grammar are to blame.
The parser implementation file is a C/C++/Java program and you can use debuggers on it, but it’s not easy to interpret what it is doing. The parser function is a finite-state machine interpreter, and aside from the actions it executes the same code over and over. Only the values of variables show where in the grammar it is working.
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
mfcalcThe debugging information normally gives the token type of each token read,
but not its semantic value. The %printer directive allows specify
how semantic values are reported, see Printing Semantic Values. For backward compatibility, Yacc like C parsers may also
use the YYPRINT (see section The YYPRINT Macro), but its use is discouraged.
As a demonstration of %printer, consider the multi-function
calculator, mfcalc (see section Multi-Function Calculator: mfcalc). To enable run-time
traces, and semantic value reports, insert the following directives in its
prologue:
/* Generate the parser description file. */
%verbose
/* Enable run-time traces (yydebug). */
%define parse.trace
/* Formatting semantic values. */
%printer { fprintf (yyoutput, "%s", $$->name); } VAR;
%printer { fprintf (yyoutput, "%s()", $$->name); } FNCT;
%printer { fprintf (yyoutput, "%g", $$); } <double>;
|
The %define directive instructs Bison to generate run-time trace
support. Then, activation of these traces is controlled at run-time by the
yydebug variable, which is disabled by default. Because these traces
will refer to the “states” of the parser, it is helpful to ask for the
creation of a description of that parser; this is the purpose of (admittedly
ill-named) %verbose directive.
The set of %printer directives demonstrates how to format the
semantic value in the traces. Note that the specification can be done
either on the symbol type (e.g., VAR or FNCT), or on the type
tag: since <double> is the type for both NUM and exp,
this printer will be used for them.
Here is a sample of the information provided by run-time traces. The traces are sent onto standard error.
$ echo 'sin(1-1)' | ./mfcalc -p Starting parse Entering state 0 Reducing stack by rule 1 (line 34): -> $$ = nterm input () Stack now 0 Entering state 1 |
This first batch shows a specific feature of this grammar: the first rule
(which is in line 34 of ‘mfcalc.y’ can be reduced without even having
to look for the first token. The resulting left-hand symbol ($$) is
a valueless (‘()’) input non terminal (nterm).
Then the parser calls the scanner.
Reading a token: Next token is token FNCT (sin()) Shifting token FNCT (sin()) Entering state 6 |
That token (token) is a function (FNCT) whose value is
‘sin’ as formatted per our %printer specification: ‘sin()’.
The parser stores (Shifting) that token, and others, until it can do
something about it.
Reading a token: Next token is token '(' ()
Shifting token '(' ()
Entering state 14
Reading a token: Next token is token NUM (1.000000)
Shifting token NUM (1.000000)
Entering state 4
Reducing stack by rule 6 (line 44):
$1 = token NUM (1.000000)
-> $$ = nterm exp (1.000000)
Stack now 0 1 6 14
Entering state 24
|
The previous reduction demonstrates the %printer directive for
<double>: both the token NUM and the resulting nonterminal
exp have ‘1’ as value.
Reading a token: Next token is token '-' () Shifting token '-' () Entering state 17 Reading a token: Next token is token NUM (1.000000) Shifting token NUM (1.000000) Entering state 4 Reducing stack by rule 6 (line 44): $1 = token NUM (1.000000) -> $$ = nterm exp (1.000000) Stack now 0 1 6 14 24 17 Entering state 26 Reading a token: Next token is token ')' () Reducing stack by rule 11 (line 49): $1 = nterm exp (1.000000) $2 = token '-' () $3 = nterm exp (1.000000) -> $$ = nterm exp (0.000000) Stack now 0 1 6 14 Entering state 24 |
The rule for the subtraction was just reduced. The parser is about to
discover the end of the call to sin.
Next token is token ')' ()
Shifting token ')' ()
Entering state 31
Reducing stack by rule 9 (line 47):
$1 = token FNCT (sin())
$2 = token '(' ()
$3 = nterm exp (0.000000)
$4 = token ')' ()
-> $$ = nterm exp (0.000000)
Stack now 0 1
Entering state 11
|
Finally, the end-of-line allow the parser to complete the computation, and display its result.
Reading a token: Next token is token '\n' () Shifting token '\n' () Entering state 22 Reducing stack by rule 4 (line 40): $1 = nterm exp (0.000000) $2 = token '\n' () ⇒ 0 -> $$ = nterm line () Stack now 0 1 Entering state 10 Reducing stack by rule 2 (line 35): $1 = nterm input () $2 = nterm line () -> $$ = nterm input () Stack now 0 Entering state 1 |
The parser has returned into state 1, in which it is waiting for the next expression to evaluate, or for the end-of-file token, which causes the completion of the parsing.
Reading a token: Now at end of input. Shifting token $end () Entering state 2 Stack now 0 1 2 Cleanup: popping token $end () Cleanup: popping nterm input () |
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
YYPRINT MacroBefore %printer support, semantic values could be displayed using the
YYPRINT macro, which works only for terminal symbols and only with
the ‘yacc.c’ skeleton.
If you define YYPRINT, it should take three arguments. The parser
will pass a standard I/O stream, the numeric code for the token type, and
the token value (from yylval).
For ‘yacc.c’ only. Obsoleted by %printer.
Here is an example of YYPRINT suitable for the multi-function
calculator (see section Declarations for mfcalc):
%{
static void print_token_value (FILE *, int, YYSTYPE);
#define YYPRINT(File, Type, Value) \
print_token_value (File, Type, Value)
%}
… %% … %% …
static void
print_token_value (FILE *file, int type, YYSTYPE value)
{
if (type == VAR)
fprintf (file, "%s", value.tptr->name);
else if (type == NUM)
fprintf (file, "%d", value.val);
}
|
| [ << ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
This document was generated by Rick Perry on December 29, 2013 using texi2html 1.82.