


Next: First Order Gauss Markov
Up: MAP Sequence Estimation for
Previous: Introduction
In the discrete-time FIR model of a fast-fading, frequency-selective
noisy communications channel, for the received data sequence up to time
n, the complex received data rk at time k is given by
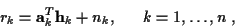 |
(1) |
where
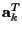 is a complex row vector containing transmitted data
{
is a complex row vector containing transmitted data
{
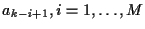 }, M is the FIR channel length,
}, M is the FIR channel length, 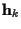 is a complex column vector containing the channel impulse response
coefficients at time k, and nk is the white Gaussian complex noise at
time k with variance
is a complex column vector containing the channel impulse response
coefficients at time k, and nk is the white Gaussian complex noise at
time k with variance 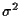 .
Let
.
Let
![${\bf H} = [{\bf h}_1, \ldots , {\bf h}_n]$](img10.gif) represent the matrix
of channel coefficient vectors over time, arranged by columns.
Let
represent the matrix
of channel coefficient vectors over time, arranged by columns.
Let
![${\bf A} = [{\bf a}_1, \ldots , {\bf a}_n]^T$](img11.gif) represent the
matrix of transmitted data arranged by rows.
Also let
represent the
matrix of transmitted data arranged by rows.
Also let
![${\bf r} = [ r_1 , \ldots , r_n ]^T$](img12.gif) represent the column vector
of received data, and
represent the column vector
of received data, and
![${\bf n} = [ n_1 , \ldots , n_n ]^T$](img13.gif) represent
the column vector of noise over time.
With this notation, the probability density function of the received
data, given
represent
the column vector of noise over time.
With this notation, the probability density function of the received
data, given 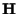 and
and 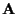 ,
is
,
is
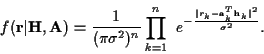 |
(2) |
The basic equations above describe the communication system under
consideration, based only on the fact that the additive noise is white
and Gaussian, without making any additional assumptions about the
properties of the FIR channel itself.
To minimize BER, the MAP criterion should be used, i.e. we must find to maximize
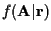 .
Using Bayes rule,
.
Using Bayes rule,
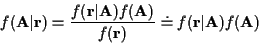 |
(3) |
(The notation 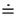 means ``equivalent within an additive and/or
multiplicative constant'' for equations in which such constants have no
effect for optimization purposes.)
In (3), the term
means ``equivalent within an additive and/or
multiplicative constant'' for equations in which such constants have no
effect for optimization purposes.)
In (3), the term
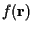 is ignored since it has no effect
in the relative cost. MAP estimators minimize BER by maximizing
is ignored since it has no effect
in the relative cost. MAP estimators minimize BER by maximizing
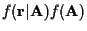 .
If
.
If
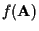 is unknown or assumed to be uniform, then the ML estimator
which maximizes the likelihood function
is unknown or assumed to be uniform, then the ML estimator
which maximizes the likelihood function
 can be used
instead. Referring to (2), if the channel is known, the
Viterbi algorithm can be used directly to estimate the data sequence.
If the channel is unknown,
the dependence of
on the random channel coefficients is
can be used
instead. Referring to (2), if the channel is known, the
Viterbi algorithm can be used directly to estimate the data sequence.
If the channel is unknown,
the dependence of
on the random channel coefficients is
![\begin{displaymath}f({\bf r}\vert{\bf A}) =
E[f({\bf r}\vert{\bf H},{\bf A})] =
...
...\bf H}} f({\bf r}\vert{\bf H},{\bf A})
f({\bf H }) d{\bf H } ,
\end{displaymath}](img24.gif) |
(4) |
where
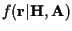 is given by (2).
is given by (2).
Given prior information on the distribution of the channel coefficient
vector sequence ,
in the form of a joint probability density
function
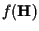 ,
(3) and (4)
may be evaluated to derive the MAP sequence estimator.
,
(3) and (4)
may be evaluated to derive the MAP sequence estimator.
Next: First Order Gauss Markov
Up: MAP Sequence Estimation for
Previous: Introduction
Rick Perry
2001-03-19