


Next: Numerical Examples
Up: The MHT Viterbi Algorithm
Previous: The MHT Viterbi Algorithm
The list-Viterbi implementation prunes the number of hypotheses out of
stage m to
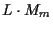 .
The value of L required to achieve a
certain level of performance can be reduced by merging similar paths
into a state prior to pruning the number of paths to L. This way,
the list of L will contain diverse hypotheses, which is the objective
(i.e. we want to keep some less-likely, significantly different hypotheses
on the chance that they will become part of more likely hypotheses later in
time).
.
The value of L required to achieve a
certain level of performance can be reduced by merging similar paths
into a state prior to pruning the number of paths to L. This way,
the list of L will contain diverse hypotheses, which is the objective
(i.e. we want to keep some less-likely, significantly different hypotheses
on the chance that they will become part of more likely hypotheses later in
time).
In order to merge similar paths, a criteria must be established to
determine whether paths are similar enough to be merged. The criteria
used in our simulation code follows. Tracks are merged if:
- 1.
- they end on the same trellis state and state permutation,
or if some of the K tracks end in a sequence of missed target events and
the last actual measurements used for these tracks (at some previous trellis
stage) are the same while the rest of the K tracks have common
measurements back to the this previous stage; and
- 2.
- the trellis states used for the track sets coincide for at least two
stage indices, and differ for no more than one stage index.
At each trellis state, the similar paths are first identified. For each
set of similar paths, the paths are
probabilistically averaged (as in [4]),
i.e. the associated Kalman filter states
are averaged, weighted by their normalized probabilities. The resulting
averaged Kalman states then replace the states for the most likely path in
the set, and the other similar paths are pruned.
Next: Numerical Examples
Up: The MHT Viterbi Algorithm
Previous: The MHT Viterbi Algorithm
Rick Perry
2000-05-06