Here we present computer simulations which show that the EM source location
estimation algorithm for Gaussian distributed
![]() (from Section 4.1)
performs better than CML, providing performance
closer to that of ML estimation
with known signal amplitudes. In these simulations two sources, impinging
from 14o and 16o, were equipowered, mutually uncorrelated, and
Gaussian distributed with mean 0. An equispaced linear array of 10
omnidirectional and matched sensors with half wavelength spacing was used.
SNR was measured at a sensor. Twenty independent snapshots were employed
for each estimate.
(from Section 4.1)
performs better than CML, providing performance
closer to that of ML estimation
with known signal amplitudes. In these simulations two sources, impinging
from 14o and 16o, were equipowered, mutually uncorrelated, and
Gaussian distributed with mean 0. An equispaced linear array of 10
omnidirectional and matched sensors with half wavelength spacing was used.
SNR was measured at a sensor. Twenty independent snapshots were employed
for each estimate.
To assure results were not skewed by global convergence
effects, the known signal ML algorithm was initialized using the true value
of ![]() .
To avoid global convergence effects and assure convergence of the iteration
process, the EM algorithm was initialized with the known signal ML solution.
The CML algorithm, which
minimizes
.
To avoid global convergence effects and assure convergence of the iteration
process, the EM algorithm was initialized with the known signal ML solution.
The CML algorithm, which
minimizes
![]() with respect to both
with respect to both ![]() and
and ![]() using
using
![]() ,
was also initialized with
the known signal ML solution.
,
was also initialized with
the known signal ML solution.
For the first simulation, 1000 trials were used per point in SNR. For the
EM algorithm, the temporally independent Gaussian signal amplitude model was
used and the correct signal covariances ![]() and means
and means ![]() were assumed.
Enough iterations were used to assure EM algorithm convergence.
(For the higher SNR's, the number of iterations was very large - over 100 -
although we used a generalized EM algorithm which significantly reduced
computation per iteration. In practice, a smaller number of iterations
could probably be used.)
were assumed.
Enough iterations were used to assure EM algorithm convergence.
(For the higher SNR's, the number of iterations was very large - over 100 -
although we used a generalized EM algorithm which significantly reduced
computation per iteration. In practice, a smaller number of iterations
could probably be used.)
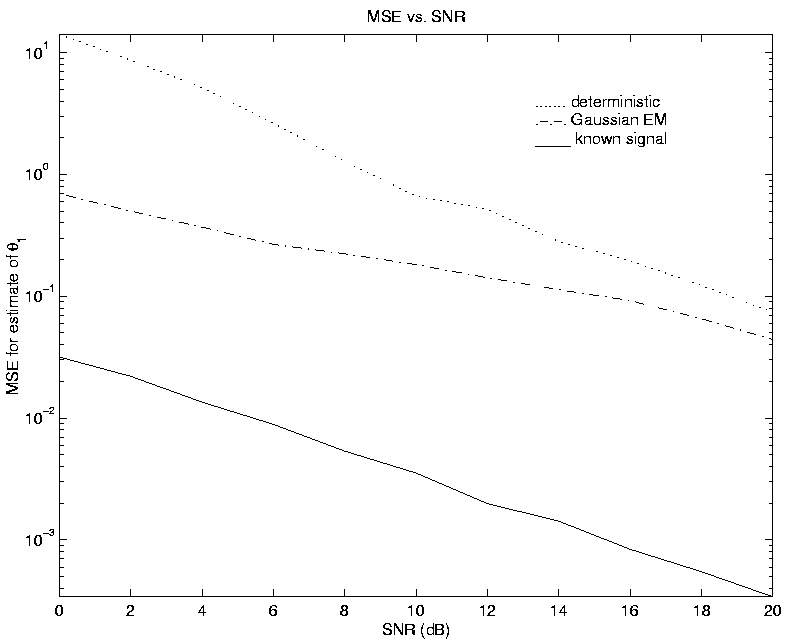
Figure 1 shows the mean-square-error in the estimate of the
14o source. The performance of the Gaussian EM algorithm is better than
the deterministic algorithm, especially at lower SNR.
From (20, 21)
we see that with zero-mean signal amplitudes and at higher
SNR, the ![]() approach the projections of the data
approach the projections of the data ![]() onto the iterating signal subspace. Asymptotically (in SNR) the EM algorithm
iteratively computes the solution to the joint location/signal estimation
problem.
onto the iterating signal subspace. Asymptotically (in SNR) the EM algorithm
iteratively computes the solution to the joint location/signal estimation
problem.
The second simulation illustrates the effect of using an incorrect prior
distribution for the signal amplitudes. Again,
the temporally independent Gaussian signal amplitude model, with zero mean,
was correctly assumed. The SNR for each of the two sources
was fixed at 8dB (i.e. 100.8 signal variance).
The signal variance for
the Gaussian prior distribution was varied from 10-2 to 103 (the
model correctly assumed the sources were mutually uncorrelated and zero mean).
2000 trials were used. Again, enough iterations were used to
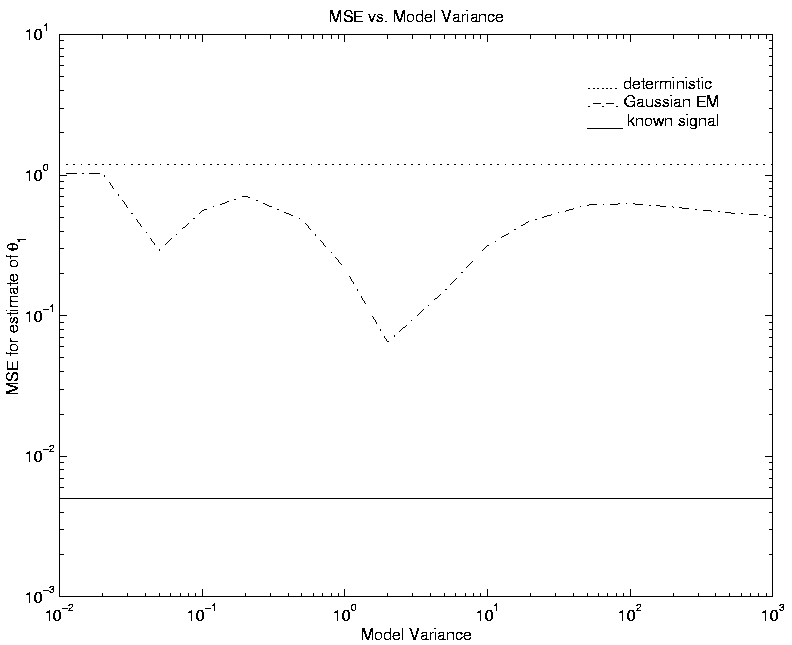
assure EM algorithm convergence. Figure 2 shows the
mean-square-error, in the estimate of the 14o source, for the EM
algorithm as a function of model variance. Also shown are the
mean-squared-error for known signal ML and CML estimators
(which are not a function of model variance). For model variance too small,
performance is degraded. This should be expected since the marginalization
over ![]() is then based on a prior that does not represent the actual
signal values.
When the model variance is larger than that for the actual signal
amplitudes, performance also degrades. However, this degradation is not as
substantial, since the model still does represent the actual signal values.
As the model variance increases, performance asymptotically approaches that
realized with a noninformative prior (e.g. [4]). This illustrates the
advantage of marginalization even when an accurate prior can not be
identified.
is then based on a prior that does not represent the actual
signal values.
When the model variance is larger than that for the actual signal
amplitudes, performance also degrades. However, this degradation is not as
substantial, since the model still does represent the actual signal values.
As the model variance increases, performance asymptotically approaches that
realized with a noninformative prior (e.g. [4]). This illustrates the
advantage of marginalization even when an accurate prior can not be
identified.