![\begin{displaymath}{\bf C} = v \; \left[ \begin{array}{ccc}
1 & 0 & 0 \\
0 & 1 & 0 \\
0 & 0 & 1 \end{array}
\right] .
\end{displaymath}](img77.gif) |
(23) |
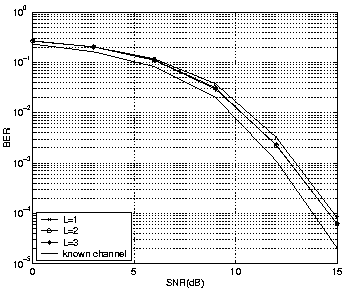
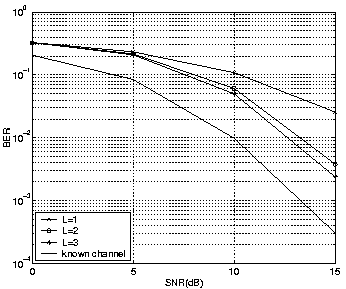
The initial channel coefficient vector ![]() is constant. The following figures show results of the GM algorithm. PSP LMS and RLS algorithms are used for comparison. The simulations were run for 1000 trials with a block length of 100. The known channel estimation is presented as a reference bound. Simulations show that when v is small, GM results approach the known channel. Figures 2 and 3 show the results when v=0.001 and v=0.01.
is constant. The following figures show results of the GM algorithm. PSP LMS and RLS algorithms are used for comparison. The simulations were run for 1000 trials with a block length of 100. The known channel estimation is presented as a reference bound. Simulations show that when v is small, GM results approach the known channel. Figures 2 and 3 show the results when v=0.001 and v=0.01.
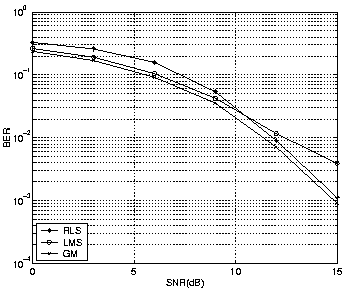
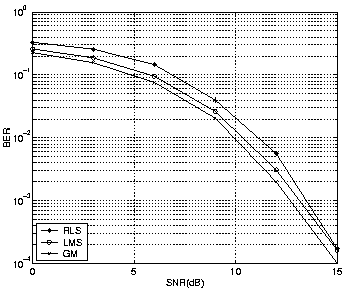
It can be observed that as L increases, the performance gets better for the same v, and the improvement is greater for larger v (i.e. for faster changing channels). Simulations also show that PSP GM performance approaches that of exhaustive search (although it is not shown in the figures). Figures 4 and 5 show the comparison of PSP LMS and RLS with GM when v is 0.01 and 0.001 respectively. The step size in LMS and forgetting factor in RLS were chosen by trial and error to obtain best possible results. The simulations show that GM performs better than PSP LMS/RLS.