Here we model the channel as described in Section III and illustrated in
Figure 1. A M = 3 tap channel is considered, with
zero-mean coefficients (i.e.
![]() )
which are
uncorrelated across delay and have variances
)
which are
uncorrelated across delay and have variances
![]() .
For each trial, a n=100 symbol transmission is simulated, with
.
For each trial, a n=100 symbol transmission is simulated, with ![]() generated using the assumed
generated using the assumed ![]() statistics noted above.
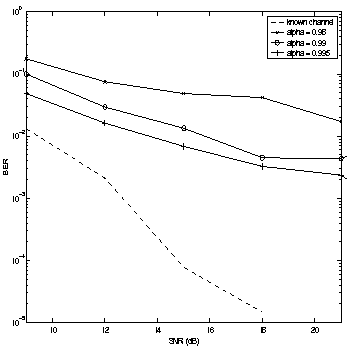
Figure 2 shows achieved bit-error-rates (BER's) for
three values of
statistics noted above.
Figure 2 shows achieved bit-error-rates (BER's) for
three values of ![]() :
0.98, 0.99, and 0.995.
Performance is probably unexceptable for
:
0.98, 0.99, and 0.995.
Performance is probably unexceptable for
![]() ,
and
as expected performance improves for increasing
,
and
as expected performance improves for increasing ![]() (i.e. reduced
fading rate).
Eventually, as SNR increases, performance improvement becomes negligible,
corresponding to a channel-uncertainty limited mode of operation.
Even for very fast fading channels, very good performance can be achieved
if the channel is known. However, when the channel is unknown,
temporal correlation is an important performance factor. The larger the
temporal correlation (i.e. the closer
(i.e. reduced
fading rate).
Eventually, as SNR increases, performance improvement becomes negligible,
corresponding to a channel-uncertainty limited mode of operation.
Even for very fast fading channels, very good performance can be achieved
if the channel is known. However, when the channel is unknown,
temporal correlation is an important performance factor. The larger the
temporal correlation (i.e. the closer
![]() is to one for a
Gauss-Markov channel), the better the sequence of symbols can be estimated.
is to one for a
Gauss-Markov channel), the better the sequence of symbols can be estimated.
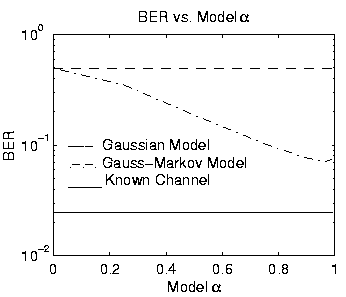
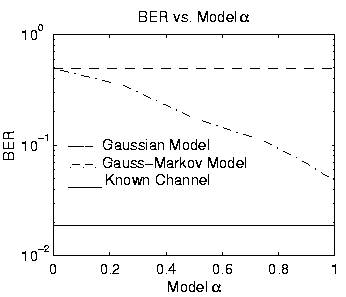
Next we consider the sensitivity of the Gauss-Markov channel model based MAP sequence estimator to assumed model parameters. For Figures 3-5, n=10 symbols were used, and the optimum Gauss-Markov model results were obtained by exhaustive search. This allows us to accurately measure the model parameter sensitivity without affects which may be caused by the sub-optimum PSP approach.
Figures 3 and 4 illustrate the sensitivity to the
assumed value of ![]() for two different values of true
for two different values of true ![]() .
For model
.
For model ![]() = 0, the Gauss-Markov channel model degenerates to a
temporally-independent Gaussian model (see [8]). Although there is
significant performance variation over the range
= 0, the Gauss-Markov channel model degenerates to a
temporally-independent Gaussian model (see [8]). Although there is
significant performance variation over the range
![]() ,
over the range of useful
,
over the range of useful ![]() (say
(say
![]() ), performance does not vary
significantly.
), performance does not vary
significantly.
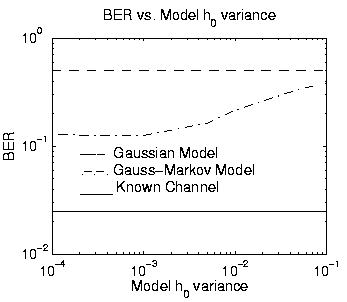
For Figure 5, the true value of ![]() was used in the
Gauss-Markov
model, but the assumed value of
was used in the
Gauss-Markov
model, but the assumed value of ![]() was randomly perturbed by adding a
zero-mean Gaussian component. For variance of the perturbation less than .001,
performance is unaffected. As the variance increases, performance degrades
and approaches the Gaussian model. This illustrates that the algorithm
is not overly sensitive to errors in the assumed value of
was randomly perturbed by adding a
zero-mean Gaussian component. For variance of the perturbation less than .001,
performance is unaffected. As the variance increases, performance degrades
and approaches the Gaussian model. This illustrates that the algorithm
is not overly sensitive to errors in the assumed value of ![]() .
Thus, using an
.
Thus, using an ![]() estimated from a previous data block is
possible.
estimated from a previous data block is
possible.