


Next: Marginalization for Number of
Up: MAP Based Estimation of
Previous: MAP Based Estimation of
We begin with a MAP formulation, which incorporates prior track set
probabilities, for the estimation of both the number of tracks K and the
tracks themselves (i.e. the track set associations
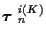 ). At time n we have the following
optimization problem. For
). At time n we have the following
optimization problem. For
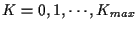 and
and
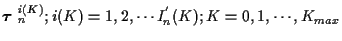
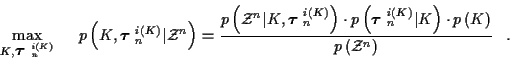 |
(8) |
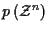 is a normalizing factor which
serves to make the possible values of
is a normalizing factor which
serves to make the possible values of
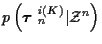 sum to
unity, and can be ignored since it is independent of
and K.
Concerning p(K), any prior distribution can be incorporated. However,
here we will assume that K is uniformly distributed from K=0 to some
maximum value
K = Kmax.
The term
sum to
unity, and can be ignored since it is independent of
and K.
Concerning p(K), any prior distribution can be incorporated. However,
here we will assume that K is uniformly distributed from K=0 to some
maximum value
K = Kmax.
The term
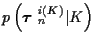 is the a priori probability
of the i(K)th set of tracks, and is derived from knowledge of the sensors,
targets, noise, clutter, jammers and preprocessors, as manifested for example
as the probability of missed detections and the false alarm rate.
In Section 5 a specific
will be used for illustration purposes.
is the a priori probability
of the i(K)th set of tracks, and is derived from knowledge of the sensors,
targets, noise, clutter, jammers and preprocessors, as manifested for example
as the probability of missed detections and the false alarm rate.
In Section 5 a specific
will be used for illustration purposes.
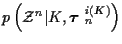 is the joint probability density function of the measurements
is the joint probability density function of the measurements
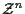 conditioned on the number of tracks K and the track set
.
For a given K and
,
we can
partition
into the data associated with the
tracks,
conditioned on the number of tracks K and the track set
.
For a given K and
,
we can
partition
into the data associated with the
tracks,
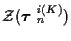 ,
and data associated with
false alarms,
,
and data associated with
false alarms,
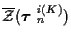 .
We then have
.
We then have
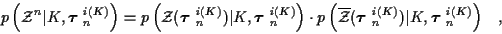 |
(9) |
where, under the assumption that false alarms are uniformly distributed
over the surveillance volume Y,
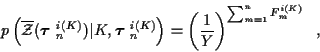 |
(10) |
where
Fmi(K) is the number of false alarms at time m given hypothesized
track set
.
In terms of the Kalman filter generated measurement innovations, for the
track measurements4,
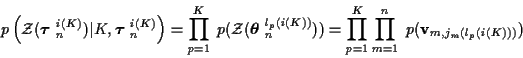 |
(11) |
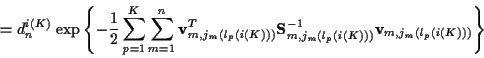 |
(12) |
where for each track p the product (or sum) over m does not include
any missed detections since as noted earlier measurements and innovations
for missed detections do not exist. Keeping this in mind,
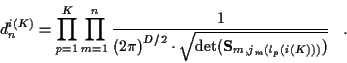 |
(13) |
Note that, for the K=0 hypothesis, there are no
measurements
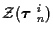 associated with tracks. Then the first
term on the right of (9) is not present. All
measurements are considered false alarms, resulting in a simple MAP probability
computation composed of (10) and a single
associated with tracks. Then the first
term on the right of (9) is not present. All
measurements are considered false alarms, resulting in a simple MAP probability
computation composed of (10) and a single
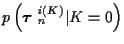 (i.e. for i(0)=1).
(i.e. for i(0)=1).
The resulting joint MAP estimator of
K and
is
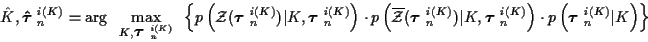 |
(14) |
where the propability is searched over all
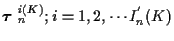 for each
.
(Referring to (5),
note that the number of hypothesized track sets for a given K is a function
of K.)
for each
.
(Referring to (5),
note that the number of hypothesized track sets for a given K is a function
of K.)
Next: Marginalization for Number of
Up: MAP Based Estimation of
Previous: MAP Based Estimation of
Rick Perry
2000-03-26