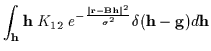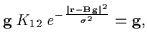The case of deterministic channel coefficients is examined first because
it is the simplest case, and because it
corresponds to the assumptions made by previously published algorithms
[3] which do not use any known apriori statistics
for the channel. Unlike the other cases considered subsequently, for
the deterministic channel we do not know the apriori mean of the
coefficients, and as shown below, the E-step of the EM algorithm
can not use
![]() .
.
If ![]() is not random, then let
is not random, then let
![]() where
where ![]() is the deterministic
but unknown value of
is the deterministic
but unknown value of ![]() , and
, and ![]() represents an impulse function.
In this case,
represents an impulse function.
In this case,
![]() , and using
(12) to estimate
, and using
(12) to estimate ![]() does not
provide anything useful since it reduces to:
does not
provide anything useful since it reduces to:
So to estimate ![]() in this case, we must use an ad-hoc method.
Note that given
in this case, we must use an ad-hoc method.
Note that given ![]() and
and ![]() ,
, ![]() satisfies (2):
satisfies (2):
In this case,
![]() , and the Viterbi algorithm incremental cost function
from (18) becomes:
, and the Viterbi algorithm incremental cost function
from (18) becomes:
In step 1 of the EM algorithm, we could initialize ![]() randomly,
or to all 1's, etc. But to reduce the number of iterations required,
and to help the algorithm converge to a proper solution, it is
better to initialize
randomly,
or to all 1's, etc. But to reduce the number of iterations required,
and to help the algorithm converge to a proper solution, it is
better to initialize ![]() with some reasonable estimate of
with some reasonable estimate of ![]() .
This can be done, for example, by initially using a pure delay channel, i.e. using
.
This can be done, for example, by initially using a pure delay channel, i.e. using
![]() in (23), then using the Viterbi algorithm to
estimate
in (23), then using the Viterbi algorithm to
estimate ![]() , then setting
, then setting ![]() to this estimate of
to this estimate of ![]() .
.
This EM algorithm is equivalent to previously published algorithms for optimal joint sequence and channel estimation [3], but the derivation here provides a mathematical basis for understanding this algorithm in the context of MLSE by marginalizing over the channel parameters.