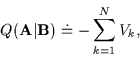Using (3) in (10),
(8) becomes:
To evaluate (11) we only need the mean and covariance of
![]() given
given ![]() and
and ![]() using the distribution of (12).
We will derive these for specific cases of
using the distribution of (12).
We will derive these for specific cases of
![]() subsequently;
for now, we define them symbolically as
subsequently;
for now, we define them symbolically as ![]() and
and ![]() :
:
The noise variance ![]() is needed in general to
compute
is needed in general to
compute ![]() and
and ![]() . If
. If ![]() is not known it could be estimated from the variances of the transmitted
and received data.
is not known it could be estimated from the variances of the transmitted
and received data.
The norm-squared term in (11), for each candidate ![]() ,
can be represented as a path through a trellis, whose states at a given
time are the states of the of the ISI channel. A path
represents a summation of incremental state transition costs.
The minimum cost path can be determined by the Viterbi algorithm.
,
can be represented as a path through a trellis, whose states at a given
time are the states of the of the ISI channel. A path
represents a summation of incremental state transition costs.
The minimum cost path can be determined by the Viterbi algorithm.
Rewriting (11) in terms of the incremental costs:
Expanding the norm squared:
Taking the expected value over ![]() :
:
Equation (18) represents the general form of the Viterbi algorithm
incremental cost function for random ISI channels.
To use (18) in an EM algorithm, ![]() and
and ![]() from
(13) and (14) are computed in the M-step; these computations
depend on the specific form of the apriori channel distribution
from
(13) and (14) are computed in the M-step; these computations
depend on the specific form of the apriori channel distribution
![]() .
The following subsections examine the specific cases of deterministic,
uniform, and Gaussian
.
The following subsections examine the specific cases of deterministic,
uniform, and Gaussian
![]() .
.