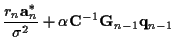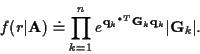For a fast time-varying channel with Gauss-Markov fading parameters,
let ![]() represent a complex first-order Markov factor such that
represent a complex first-order Markov factor such that
![]() where T is the sampling period and
where T is the sampling period and
![]() is the Doppler spread [9].
Let the time-varying channel coefficients follow a Gauss-Markov
distribution such that, at time k,
is the Doppler spread [9].
Let the time-varying channel coefficients follow a Gauss-Markov
distribution such that, at time k,
![]() ,
where
,
where ![]() is complex, white, and Gaussian
with mean
is complex, white, and Gaussian
with mean ![]() and covariance
and covariance ![]() .
In this case,
.
In this case,
![]() is Gaussian with mean
is Gaussian with mean
![]() and covariance
and covariance ![]() .
.
![]() can be written as
can be written as
We assume the mean of
![]() is zero and the initial channel coefficient is known and it is represented as
is zero and the initial channel coefficient is known and it is represented as ![]() .
So
.
So
The term
![]() in (15) is a function of
in (15) is a function of ![]() and will be involved in the integral over
and will be involved in the integral over ![]() .
The rest of the terms in (15) are the results after the integration over
.
The rest of the terms in (15) are the results after the integration over ![]() and are only decided by the input sequence and will be used to compute the maximum likelihood probability.
and are only decided by the input sequence and will be used to compute the maximum likelihood probability.
The general form of the results after integral over ![]() (
k=2,...,n-1) will be
(
k=2,...,n-1) will be
If we take the negative natural logarithm of the above equation, we will obtain the time-recursive form of the cost function. However, from the expressions of ![]() and
and ![]() we know the transition costs depend on all the previous states, so the standard Viterbi algorithm can not be applied here. The optimum results can only be obtained by exhaustive search. However, a suboptimum algorithm which we call GM may be derived and we introduce this algorithm as follows. Observe equations (16), (18) and (21). Note that the parameters in the computation of the cost such as
we know the transition costs depend on all the previous states, so the standard Viterbi algorithm can not be applied here. The optimum results can only be obtained by exhaustive search. However, a suboptimum algorithm which we call GM may be derived and we introduce this algorithm as follows. Observe equations (16), (18) and (21). Note that the parameters in the computation of the cost such as ![]() and
and ![]() are actually a function of all the previous transmitted data symbols. This observation suggests that we use per-survivor processing (PSP) [6] to decrease the computational complexity.
It is well known that if the quantities corresponding to the computation of MLSE are unknown, we may use data-aided estimation to estimate them. In PSP, these quantities are estimated by data-aided estimation, but the sequence used in data-aided estimation of the transition cost corresponding to a particular state transition is the sequence associated with the survivor path before the current transition. The path obtained this way should approach the optimum results due to reduced error propagation.
Furthermore, in our algorithm, GVA is applied [8], we compute the
are actually a function of all the previous transmitted data symbols. This observation suggests that we use per-survivor processing (PSP) [6] to decrease the computational complexity.
It is well known that if the quantities corresponding to the computation of MLSE are unknown, we may use data-aided estimation to estimate them. In PSP, these quantities are estimated by data-aided estimation, but the sequence used in data-aided estimation of the transition cost corresponding to a particular state transition is the sequence associated with the survivor path before the current transition. The path obtained this way should approach the optimum results due to reduced error propagation.
Furthermore, in our algorithm, GVA is applied [8], we compute the ![]() and
and ![]() associated with the survivors of the trellis, and these
associated with the survivors of the trellis, and these ![]() and
and ![]() are used to compute the current transition cost and to find the survivors at the next stage. At each state of each stage, we keep more than one survivor and we denote this fixed number of survivors as L. As L increases, the algorithm will approach the optimum results. This algorithm is a suboptimum but effective method for adaptive MLSE.
are used to compute the current transition cost and to find the survivors at the next stage. At each state of each stage, we keep more than one survivor and we denote this fixed number of survivors as L. As L increases, the algorithm will approach the optimum results. This algorithm is a suboptimum but effective method for adaptive MLSE.
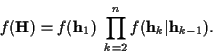
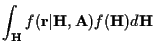
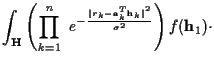
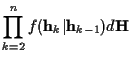
![$\displaystyle \left[
\frac {{\bf a}_1^* {\bf a}_1^T}
{\sigma^2}
+ (1 + {\vert\alpha\vert}^2){\bf C}^{-1}
\right]^{-1}$](img54.gif)
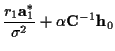
![$\displaystyle \left[
\frac {{\bf a}_k^* {\bf a}_k^T}
{\sigma^2}
+ {\bf C}^{-1}
...
...ft(
{\bf C}^{-1} - {\bf C}^{-1} {\bf G}_{k-1} {\bf C}^{-1}
\right)
\right]^{-1}$](img61.gif)
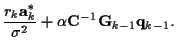
![$\displaystyle \left[
\frac {{\bf a}_n^*{\bf a}_n^T}
{\sigma^2}
+ {\bf C}^{-1}
-\vert\alpha\vert^2 {\bf C}^{-1} {\bf G}_{n-1} {\bf C}^{-1}
\right]^{-1}$](img67.gif)