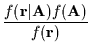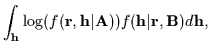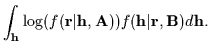To minimize BER, we must find ![]() to maximize
to maximize
![]() .
Using Bayes rule:
.
Using Bayes rule:
MAP estimators minimize BER by maximizing
![]() .
If
.
If
![]() is unknown or assumed to be uniform, then the ML estimator
which maximizes the likelihood function
is unknown or assumed to be uniform, then the ML estimator
which maximizes the likelihood function
![]() can be used instead.
All of the EM algorithms derived in the subsequent sections produce iterative
solutions to the ML problem of maximizing
can be used instead.
All of the EM algorithms derived in the subsequent sections produce iterative
solutions to the ML problem of maximizing
![]() .
But if
.
But if
![]() is known and not uniform,
then this could be incorporated into
the following EM algorithms as an additive term in the cost function,
thus producing a MAP estimator.
is known and not uniform,
then this could be incorporated into
the following EM algorithms as an additive term in the cost function,
thus producing a MAP estimator.
The dependence of
![]() on the random channel coefficients is:
on the random channel coefficients is:
The only apparent case where direct evaluation and maximization of
![]() from (5) seems tractable is if
from (5) seems tractable is if ![]() is deterministic.
Then
is deterministic.
Then
![]() and (5) reduces to (3) with
and (5) reduces to (3) with
![]() ,
where
,
where ![]() is the deterministic but unknown value of
is the deterministic but unknown value of ![]() , as discussed further in
Section 4.1. This provides a theoretical basis for the joint
, as discussed further in
Section 4.1. This provides a theoretical basis for the joint
![]() estimation algorithms such as [3].
However for arbitrary
estimation algorithms such as [3].
However for arbitrary
![]() we must work with (5) directly, or
use an EM algorithm, in order to produce optimal estimates of
we must work with (5) directly, or
use an EM algorithm, in order to produce optimal estimates of ![]() .
.
To maximize (5) using EM, define the auxiliary function [4]:
The general EM algorithm for this problem is:
In general, to construct
![]() , start with
, start with
![]() :
:
To evaluate
![]() , we need
, we need
![]() ,
which can be written in terms of the apriori channel coefficient density function
,
which can be written in terms of the apriori channel coefficient density function
![]() as:
as:
Therefore, for
![]() in (8) we may use:
in (8) we may use:
In the specific cases considered subsequently,
we will show that the E-step reduces to computing
sufficient statistics of
![]() , which are the mean and covariance of
, which are the mean and covariance of ![]() conditioned on
conditioned on ![]() and
and ![]() .
This enables the Viterbi algorithm [1] to be used for the M-step.
The Viterbi algorithm is a well-known efficient
method for ML sequence estimation over known channels. It can be used here
in the unknown channel case because of the estimates provided by the E-step.
The E-step and M-step formulas will be derived in detail in subsequent sections for
various specific channel coefficient distributions.
.
This enables the Viterbi algorithm [1] to be used for the M-step.
The Viterbi algorithm is a well-known efficient
method for ML sequence estimation over known channels. It can be used here
in the unknown channel case because of the estimates provided by the E-step.
The E-step and M-step formulas will be derived in detail in subsequent sections for
various specific channel coefficient distributions.