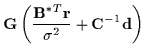Let
![]() be a joint Gaussian distribution with
mean
be a joint Gaussian distribution with
mean ![]() and covariance
and covariance ![]() :
:
The Gaussian distribution of ![]() is intermediate between the known
deterministic channel case and uniform unknown
is intermediate between the known
deterministic channel case and uniform unknown ![]() . In the limit as
. In the limit as
![]() goes to 0,
goes to 0, ![]() approaches
approaches ![]() and
and ![]() approaches known
approaches known
![]() , which corresponds to the Gaussian distribution approaching
, which corresponds to the Gaussian distribution approaching
![]() . This is similar to the case of deterministic
. This is similar to the case of deterministic
![]() from Section 4.1 except that here the mean is known
whereas in Section 4.1 it was estimated using (22).
In the limit as
from Section 4.1 except that here the mean is known
whereas in Section 4.1 it was estimated using (22).
In the limit as ![]() goes to infinity,
goes to infinity, ![]() approaches
approaches
![$\left[ \frac {{\bf B}^{*T} {\bf B}}{\sigma^2} \right]^{-1}$](img108.gif) and
and ![]() approaches
approaches
![]() , which corresponds to
the Gaussian distribution approaching a uniform distribution.
, which corresponds to
the Gaussian distribution approaching a uniform distribution.
Also, if N >> L or the noise variance is small,
the term involving ![]() in (31) can dominate the
in (31) can dominate the
![]() term, so then
term, so then ![]() approaches
which approaches 0,
and
approaches
which approaches 0,
and ![]() approaches
approaches
![]() , which corresponds to
the Gaussian EM algorithm becoming equivalent to the algorithm
for deterministic channel coefficients.
, which corresponds to
the Gaussian EM algorithm becoming equivalent to the algorithm
for deterministic channel coefficients.
Therefore, for the case of Gaussian distributed channel coefficients, the
EM algorithm is almost the same as for uniform channel coefficients,
except that the E-step
uses (31) and (32) to estimate
![]() and
and ![]() .
.
To use the Viterbi algorithm to initialize ![]() in step 1,
we could, for example, initialize
in step 1,
we could, for example, initialize
![]() and
and
![]() .
.
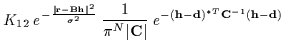
![$\displaystyle \left[
\frac {{\bf B}^{*T} {\bf B}}
{{\sigma}^2}
+ {\bf C}^{-1}
\right] ^{-1}$](img104.gif)